If I were to give you a bunch of strings, how would you store them? Perhaps as an array or a list? But what if you’re required to search for a string? That’s a search complexity of O(n) (Where n is the number of strings stored). Can this be done more efficiently?

Instead of storing words individually, perhaps the overlapping parts can be stored just once, like a tree. This type of data structure is called a Trie (Nope not a typo).
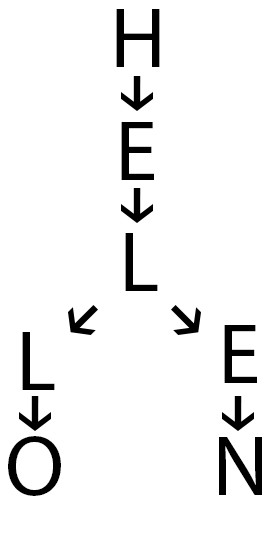
This makes searching for a string ‘ STR’ O(Length of STR)’ . This gives rise to a big problem though. What about the string ‘HEL’? This certainly wasn’t a part of the initial list but it seems to exist in our data structure. How do we differentiate between strings like ‘HEL’ and ‘HELL’? We can use 0s and 1s to indicate the existence of a string.
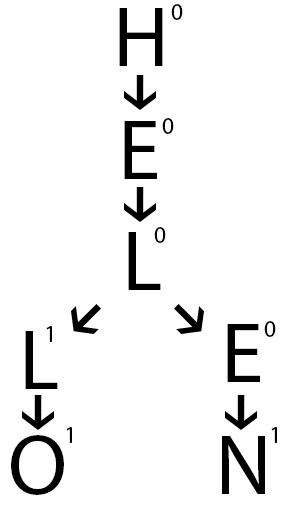
This was a very simplistic explanation of what a trie is. In reality each node holds an array of pointers (Nonexistent children are NULL values) along with a key value and the root node holds no key. Tries can be used to store a multitude of different types of data, not just strings.
If a string ‘HELE’ needs to be added, then the key value of the last ‘E’ is set to 1. If the string ‘HELLO’ needs to be deleted, the key value of the last ‘O’ is set to 0. This makes searching for a string quite trivial. For example, searching for the string ‘HE’, we start off at the root. From the root we try to move to the first letter ‘H’. Since the child ‘H’ exists, we move to it. Now we look for ‘E’ from ‘H’. Since the child ‘E’ exists, we move to it. As we have reached the end of the string, we look at the key value of ‘E’. ‘E’ has a key value of 0 which means the string ‘HE’ doesn’t exist in our data structure.
On the surface a trie might seem to be more space efficient than a simple list but tries grow very quickly and each node holds a lot of pointers. In the case of the English alphabet, each node holds 26 pointers, so that’s a lot of useless pointers holding only NULL values. In the above example the root node would have 25 NULL children since only child exists (H). Similarly with the ‘H’ and ‘E’ nodes. So we’re sacrificing memory to improve our running time.
Tries are an extremely useful data structure. They are used to implement (Albeit in a much more complex manner) search and auto-complete suggestions, look-ups for blacklisted/whitelisted IP addresses, spell-checkers and many more interesting things.
If you’d like to learn more, Radix Trees are a step up, they occupy less space compared to tries while maintaining the running time.
– Ajay Bharadwaj