Have you ever wondered what happens when you search for something on google? How does google manage to find the most useful data from such a huge collection of webpages
Organizing Data
This is basically done in two steps : Crawling and Indexing
- Crawling
This happens before the search. The web crawlers gather information from billions of web pages. The way they work is interesting. They visit webpages obtained from previous crawls and other data provided by website owners. Then they find links on those pages and travel through to discover new pages. They provide data from these pages to the Google servers.
- Indexing
As crawling happens, each webpage is rendered and the systems collect all the key data from the page. All this data is kept track of in the search index. The Google Search index contains hundreds of billions of webpages and is well over 100,000,000 gigabytes in size. It’s like the index in the back of a book — with an entry for every word seen on every webpage we index.
Searching
With so much data on the web, finding necessary information would be impossible without filtering and sorting it. So, google uses a set of algorithms.
- Understanding the query
The intent behind the query has to be first understood. It basically involves understanding the language, correct errors, etc. Google has an algorithm to interpret spelling mistakes, match keywords to their respective meanings in the query (if it has multiple meanings). It is done mainly using natural language processing.
- Quality of content
The Page Rank Algorithm which was developed by Larry Page and Sergey Brin, is a unique algorithm that ranks the webpages based on the links that are coming into and going out of a page. It basically determines the page’s reliability and importance.
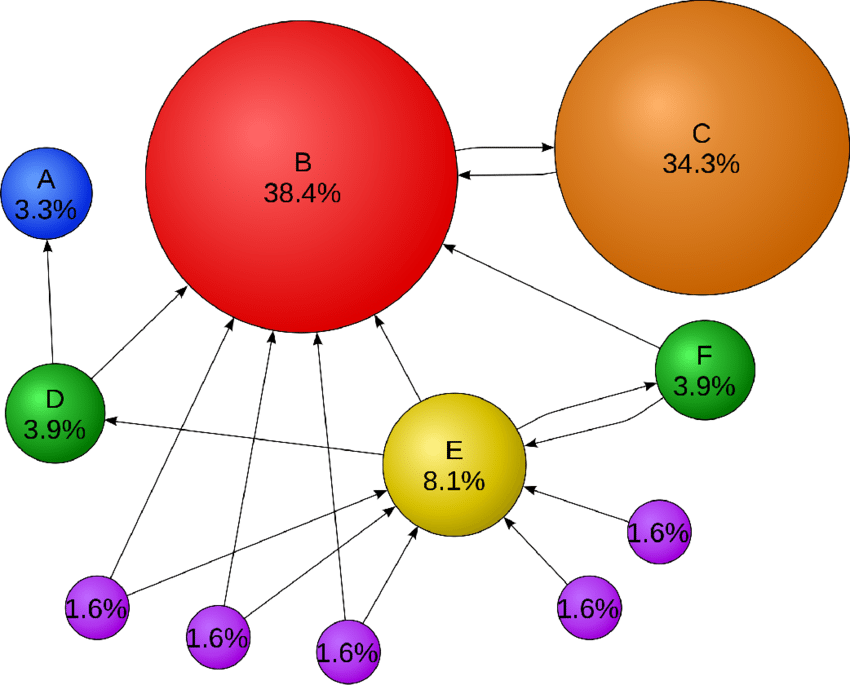
Page C has higher rank than page E even though it has one link. It is because the link that comes to C is from a more important page and hence has higher value. If web surfers who start on a random page have an 85% likelihood of choosing a random link from the page they are currently visiting, and a 15% likelihood of jumping to a page chosen at random from the entire web, they will reach Page E 8.1% of the time.
- Relevance of webpages
The content of a webpage is assessed by the use of an algorithm. Beyond simple keyword matching, an aggregated and anonymized interaction data is used to check whether search results are relevant to queries. It means that the algorithm looks for more content on the page (like pictures and videos) which are relevant.
- Usability of webpages
The algorithm checks for the usability of the webpage. Pages which are easier to use are given more priority. It checks whether the page opens properly in different browsers, its compatibility in different devices, etc.
Google informs the website owners about the changes it will bring in the algorithm so that they make necessary changes to make it more easily usable.
- Context and settings
This is a very important part which makes the google search more user friendly and relevant. This algorithm uses the users search history, location and search settings to provide the most useful results. Search also personalizes based on the activity in the google account. Google also allows the user to control the search settings.
Next time you search something on google you actually know what is going on behind.
– Hardik Harti