What are Group Membership Protocols?
In data centers, failures are the norm rather than the exception. Google fellow Jeff Dean offers an overview of Google’s data center operations:
“In each cluster’s first year, it’s typical that 1,000 individual machine failures will occur; thousands of hard drive failures will occur; one power distribution unit will fail, bringing down 500 to 1,000 machines for about 6 hours; 20 racks will fail, each time causing 40 to 80 machines to vanish from the network; 5 racks will “go wonky,” with half their network packets missing in action; and the cluster will have to be rewired once, affecting 5 percent of the machines at any given moment over a 2-day span, Dean said. And there’s about a 50 percent chance that the cluster will overheat, taking down most of the servers in less than 5 minutes and taking 1 to 2 days to recover.”
We need a mechanism to detect failures and disseminate the failure information through the network. This is where Group Membership Protocols come into picture. We give every process a membership list. A membership list contains the list of all processes along with its last heartbeat. (Heartbeat refers to the last time the process P communicated with the current process.)
Now that every process has a membership list, we need to detect failures. Once a failure is detected, this process needs to be removed from all membership lists. How do we achieve this?
Heartbeat Protocol
A process P sends a heartbeat(message) to process Q telling that it is alive. If P does not receive the heartbeat, it assumes that process Q is dead.
The topology could be varied. All processes might send heartbeats to a centralized node or they could send it to all other processes.
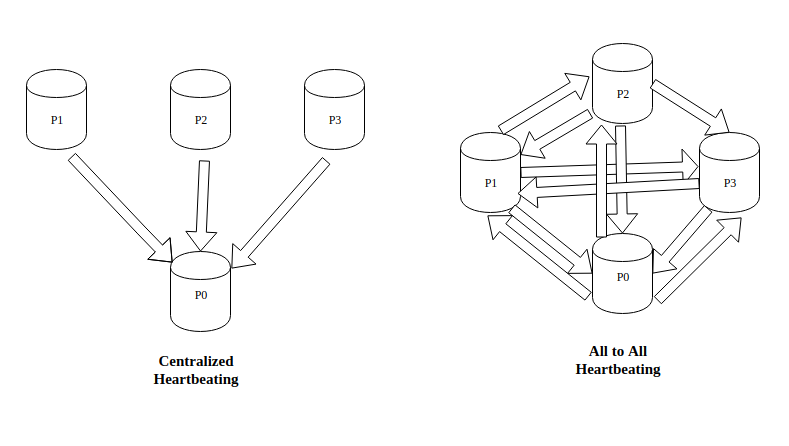
There are some very obvious disadvantages here. Centralized Heartbeat-ing is dependent on one central process. If that fails, everything fails. All to All Heartbeat-ing has an increased overhead of sending heartbeats to all the processes.
So how do we optimise?
Gossip- Style Membership
Every process randomly selects n processes and sends them a heartbeat. Each of these processes will update their membership lists and send out a heartbeat to n processes again randomly selected. If the heartbeat does not increase even after T_fail seconds, the process is considered fail. It waits for another T_cleanup seconds before it deletes the member from the membership list.
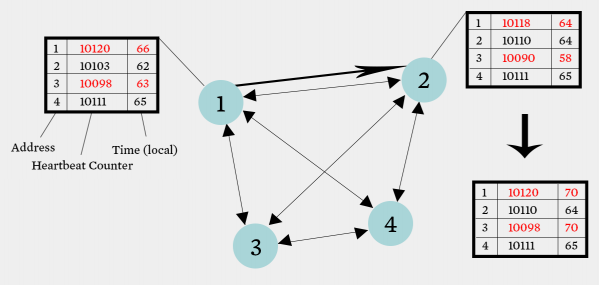
A single heartbeat takes O(log N) time to propagate and N heartbeats take O(N log(N)) time.
Can we optimize further?
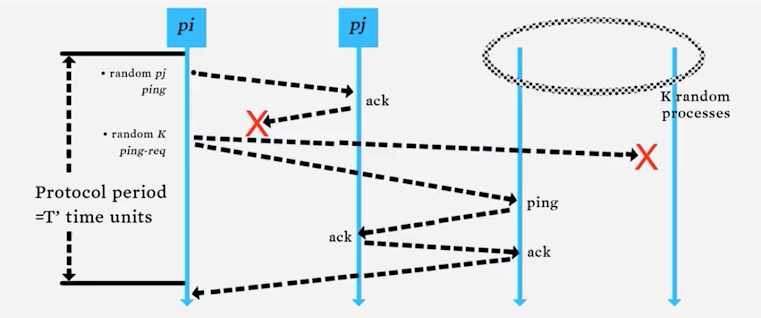
SWIM Failure Detector Protocol
SWIM (Scalable Weakly-consistent Infection-style) uses membership lists along with a protocol period T. A process Pi randomly picks a process Pj in its membership list and pings it. If it does not receive an ACK within the timeout period, it selects k other targets and uses them to send a message to Pj. The ACK is passed on from these k targets to Pi. If Pi doesn’t receive an ACK within T, it declares Pj as failed.